前言
这篇博文会介绍如何使用CUDA 在屏幕上打出Hello World!
直接上代码
#include <stdio.h>
#include <cuda_runtime.h>
__host__ void cpuSayHello() {
printf("CPU: hello world!\n");
}
__device__ int getThreadID() {
return threadIdx.x;
}
__global__ void sayHello() {
printf("GPU: hello world!\n");
printf("GPU thread ID : %d \n", getThreadID());
}
int main()
{
sayHello<<<1, 3 >>> ();
cpuSayHello();
cudaDeviceSynchronize();
return 0;
}
运行结果:
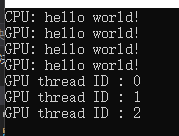
这个代码和纯C/C++代码有所不同,主要在于函数的调用方式,和在定义函数时在前面加了 host global device 三个关键字。
关键字 host global device
这三个关键字用于定义函数的类型。
- global 修饰的函数,被定义为核函数,可以在普通函数类使用特殊方法调用,调用之后函数会在GPU上运行,需要注意的是,核函数的返回值必须是void。
- device 修饰的函数,表示可以在GPU中调用的函数,只能在核函数或者被device 修饰的函数中被调用,这种函数可以有返回值。
- host 修饰的函数为普通函数,和C/C++的函数性质一样,这个关键字是默认的,如果在.cu文件中函数定义时没有使用关键字修饰,那么默认就是host。
核函数的调用方式
核函数的调用方式,与普通函数不同,调用格式为:
FunctionName<<<blockSize,threadSize>>>(par);
FunctionName: 函数名
blockSize: 线程块的数量
threadSIze: 线程数量
par:函数参数,可以有多个
同步
从运行结果的输出顺序可知,核函数先被调用,而先输出是 “CPU:hello world!” ,调用核函数只是将计算任务扔给GPU,并不会等到所有的核函数中的代码执行完成再继续往下执行。所以再调用完核函数之后,可以根据自己需求,是否要等待同步。
等待同步的函数为:
cudaDeviceSynchronize()
这个函数会阻塞线程,直到GPU上的任务执行完成后。


文章评论