前言
这是对官方文档中对占用率解释的部分的翻译。原文: 点击前往
在原文的基础上增加了自己的一些评述,不一定对,看个乐呵。
概述
在CUDA的Profile和Trace模式下记录的所有CUDA核函数启动中的Occupancy(占用率)实验详情窗格显示“理论占用率”,即由核函数启动配置和CUDA设备的能力强加的占用率上限。在Profile模式的Achieved Occupancy实验中,测量了核函数执行期间的占用率,并将实际值添加到Occupancy实验详情窗格中,与理论值一起显示。额外的图表显示每个SM的实际占用率,并说明通过改变编译器和启动参数可以控制占用率。这些数据和图表有助于开发人员分析核函数在GPU上的执行情况,优化占用率以提高性能。
占用率的定义
CUDA C编程指南解释了CUDA设备的硬件实现是如何将块内相邻的线程分组成线程束(warp)的。线程束在其线程开始执行时被视为活动,直到线程束中的所有线程都从核函数中退出为止。在流处理多处理器(SM)上可以同时活动的线程束存在最大数量,如编程指南的计算能力表中所列。占用率被定义为SM上活动线程束的数量与SM支持的最大活动线程束数量的比率。由于线程束的开始和结束,占用率随时间变化,并且每个SM的占用率可能不同。
低占用率会导致指令发射效率低下,因为没有足够的符合条件的线程束来隐藏依赖指令之间的延迟。当占用率达到足够的水平以隐藏延迟时,进一步增加占用率可能会因为每个线程的资源减少而降低性能。对核函数性能分析的早期步骤应该是检查占用率,并观察在不同占用率水平下运行时对核函数执行时间的影响。
这里应该是指内存延迟?比如当线程中进行全局内存访问时,需要相当多的时间,那么就需要把当前的线程“挂起”,从而去执行那些指令中暂时没有延迟的指令。通过这个操作就可以隐藏掉访问内存时的延迟。
理论占用率
有一个活动线程束的上限,因此也有一个占用率的上限,可以从启动配置、核函数的编译选项和设备能力中推导出。每个核函数启动的块都被分配到一个SM上进行执行。一个块在其线程束开始执行时被视为活动,直到块中的所有线程束都从核函数中退出为止。
有一个活动线程束的上限,因此也有一个占用率的上限,可以从启动配置、内核的编译选项和设备能力中推导出。每个内核启动的块都被分配到一个SM上进行执行。一个块在其线程束开始执行时被视为活动,直到块中的所有线程束都从内核中退出为止。
在一个SM上可以同时执行的块的数量受到以下因素的限制:
- GPU的最大活动块数
- GPU的最大线程束,SM单元上的活动块中的线程束与活动块数量的乘积不能超过这个数值。
因此,可以通过增加每个块的线程束数量(由块的维度定义)或更改限制有多少块可以适应一个SM的因素来提高活动线程束的上限,以允许更多的活动块。
每个SM单元上的线程束
SM具有同时活动的线程束的最大数量。由于占用率是活动线程束与最大支持的活动线程束的比率,如果活动线程束的数量等于最大值,那么占用率就是100%。如果这个因素限制了活动块,那么占用率就无法增加。例如,在一个支持每个SM 64个活动线程束的GPU上,每个块有256个线程(每个块8个线程束)的情况下,8个活动块会导致64个活动线程束,理论上的占用率为100%。同样,如果每个块有128个线程(每个块4个线程束),那么16个活动块也会导致64个活动线程束,理论上的占用率为100%。
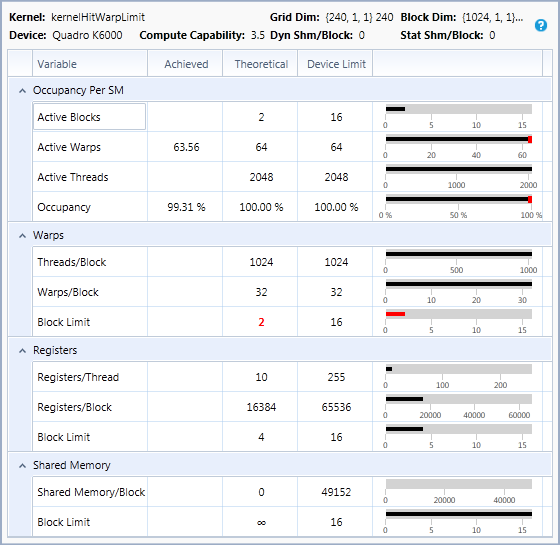
每个SM单元中的block数量
SM有一个可以同时活动的块的最大数量。如果占用率低于100%并且这个因素限制了活动块,那么这意味着当设备的活动块限制达到时,每个块中没有足够的线程束来达到100%的占用率。通过增加块的大小可以提高占用率。例如,在一个支持每个SM 16个活动块和64个活动线程束的GPU上,每个块有32个线程(每个块1个线程束)的情况下,最多只能有16个活动线程束(理论上的占用率为25%),因为只有16个块可以是活动的,并且每个块只有一个线程束。在这个GPU上,将块的大小增加到每个块4个线程束,可以实现理论上的100%的占用率。
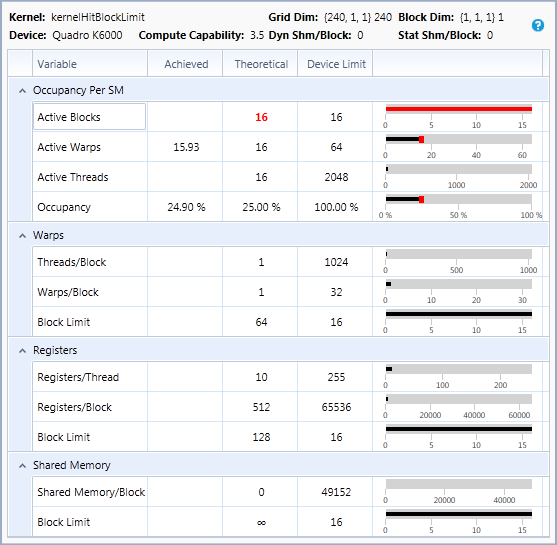
每个SM单元的寄存器数
SM有一组由所有活动线程共享的寄存器。如果这个因素限制了活动块,这意味着编译器为每个线程分配的寄存器数量可以减少以增加占用率。在调整每个线程的寄存器数以控制占用率时,应仔细监控内核执行时间和平均符合条件的线程束。由于占用率的增加导致的改善潜在延迟隐藏可能被每个线程的寄存器减少以及更频繁地溢出到本地内存所导致的性能损失所抵消。通过对使用不同寄存器数编译的内核进行实验,通过 __launch_bounds__ 进行控制,可以找到最佳的占用率和每个线程的寄存器数的平衡点。
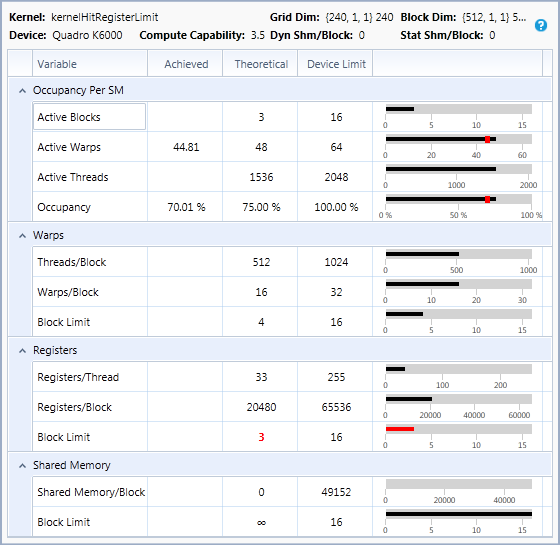
每个SM单元上的共享内存
SM有一定数量的共享内存,由所有活动线程共享。如果这个因素限制了活动块,这意味着可以减少每个线程所需的共享内存以增加占用率。每个线程的共享内存是 "静态共享内存"(所有 shared 变量所需的总大小)和 "动态共享内存"(作为内核启动参数指定的共享内存的数量)的总和。对于一些CUDA设备,每个SM上的共享内存量是可配置的,可以在共享内存大小和L1缓存大小之间进行权衡。如果这样的GPU被配置为使用更多的L1缓存,而共享内存是占用率的限制因素,那么通过选择使用更少的L1缓存和更多的共享内存,也可以增加占用率。
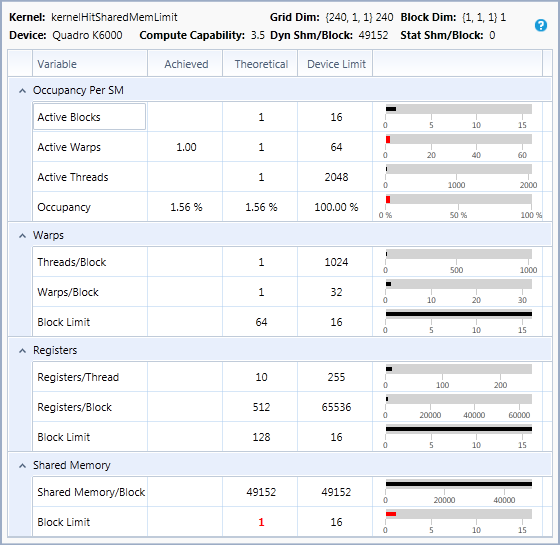
上面列举了线程束数量、块大小、寄存器数量和共享内存大小对占用率影响。
在我看来,就是所有的资源都是有上线的,无论是寄存器,共享内存还是GPU对每个SM单元的最大活动线程束、活动块等等的限制。只要上述的一种资源,超出了SM单元的资源数量,那么就会影响到SM单元上能运行的线程束的数量。
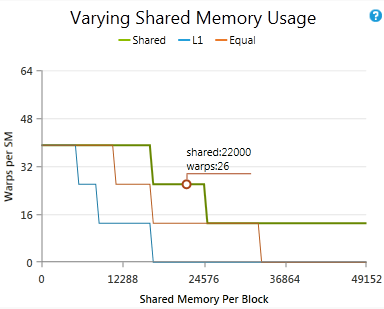
比如共享内存的那张图例里,由于一个块需要使用49152的共享内存,而这个大小刚好将SM单元中的共享内存用完了,所以即使这个SM单元的线程束资源,还剩余非常多,但是依然只能有一个活动块,最后导致极地的占用率。
唯一比较疑惑的是这个图例:
这张图里,因为每个块中只有一个线程,而GPU的每个SM单元的最大活动块是16,那么也就是说这个SM单元中将只会有16个块运行,16个线程束,按照占用率的定义,理论占用率是25%。
但是这里每个线程束中只有一个线程,因为32个线程为一个线程束,那么这里每个线程束相当于浪费了31个线程,所以我在想占用率是否无法精确的提现代码对GPU的使用率?
理论占用率
理论上的占用率显示了SM上活动线程束的上限,但在内核的执行过程中,真实的活动线程束数量会随着线程束的开始和结束而变化。正如在“指令效率”中所解释的,一个SM包含一个或多个线程束调度器。每个线程束调度器尝试在每个时钟周期中为一个线程束发射指令。为了充分隐藏依赖指令之间的延迟,每个调度器必须至少有一个线程束有资格在每个时钟周期中发射一条指令。在内核执行过程中保持尽可能多的活动线程束(高占用率)有助于避免所有线程束都停滞而没有发射指令的情况发生。实际占用率是使用硬件性能计数器在每个线程束调度器上测量的,用于计算该调度器上每个时钟周期中的活动线程束数量。然后将这些计数在每个SM上的所有线程束调度器上累加,并除以SM活动的时钟周期数,以找到每个SM上的平均活动线程束数量。通过SM支持的最大活动线程束数量进行除法,得到了在内核执行过程中平均每个SM上实际的占用率,该值显示在实际占用率图表中。对所有SM进行平均得到总体实际占用率,该值与实验详细信息窗格中的理论占用率一起显示。
占用率低的原因
块内工作负载不平衡
如果块内的线程束在执行过程中的时间不一致,那么工作负载被称为不平衡。这意味着在内核结束时有较少的活动线程束,这是一种被称为“尾效应”的问题。最好的解决方案是尝试使每个块中的线程束之间的工作负载更加平衡。
每个块之前的工作负载不平衡
如果在一个网格内的各个块执行时间不同,这也被认为是不平衡的工作负载,但是可以在不改变为更加平衡的工作负载的情况下提高设备的效率。启动更多的块将允许新块在其他块完成时开始执行,这意味着尾效应不会发生在每个块内,而只会在内核结束时发生。如果没有更多的块可以启动,使用具有相似块属性的并发内核可能可以实现相同的效果。这种方法可以提高设备的利用率,允许设备在某些块执行较慢的情况下继续执行其他块,从而更有效地利用计算资源。
启动的块太少
每个SM上的活动块的上限由理论占用率确定,但该计算并不考虑每个SM上块的数量少于该数字的情况。设备上的SM数量乘以每个SM的最大活动块数量被称为一个 "full wave",而启动少于一个完整波的块会导致实际占用率较低。例如,在一个具有15个SM的设备上,配置期望每个SM有4个块,实现100%理论占用率,一个完整波将包含60个块。仅启动45个块(假设工作负载是平衡的)将导致实际占用率约为75%。
图表
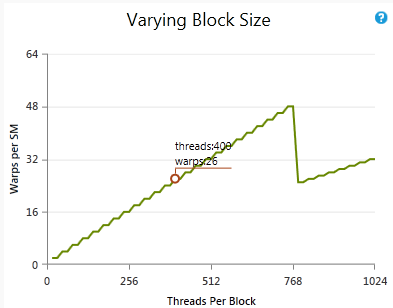
不同的块大小
展示了在保持其他参数不变的情况下,改变块大小如何影响理论占用率。圈出的点显示了当前每个块的线程数和当前活动工作组的上限。请注意,活动工作组的数量并非每个块的工作组数量(即每个块的线程数除以工作组大小,四舍五入取整)。如果图表的线高于圈出的点,改变块大小可以在不改变其他因素的情况下增加占用率。
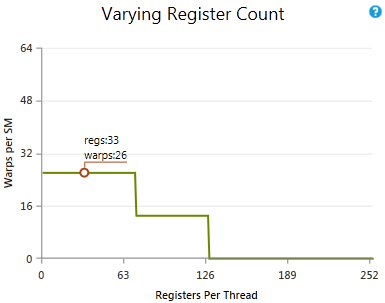
不同的寄存器数量
展示了在保持其他参数不变的情况下,改变寄存器数量如何影响理论占用率。圈出的点显示了当前每个线程的寄存器数量和当前活动工作组的上限。如果图表的线高于圈出的点,改变每个线程的寄存器数量可以在不改变其他因素的情况下增加占用率。
不同的共享内存大小
展示了在保持其他参数不变的情况下,改变共享内存使用量如何影响理论占用率。圈出的点显示了当前每个块的共享内存量和当前活动工作组的上限。如果图表的线高于圈出的点,改变每个块的共享内存量可以在不改变其他因素的情况下增加占用率。
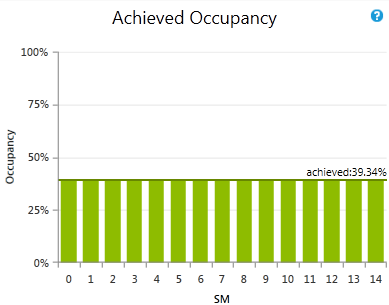
每个SM单元的占用率
每个SM的实际占用率。报告的值是在内核执行的整个持续时间内所有工作组调度器的平均值。横穿所有柱状图的线是平均值,也是其他表中作为实际占用率报告的数字。
分析
低占用率本身并不是问题,但通常会导致可执行工作组数过少。如果Warp Issue Efficiency图表中没有可执行warp的周期百分比较高尽量增加活动warp的数量。
在许多情况下,增加活动warp的数量将导致更大的可执行warp池。如果理论占用率较低,请尝试优化内核启动的执行配置,使用占用率表格确定哪个因素限制了占用率。
如果受寄存器限制,不要排除尝试使用启动边界进行实验以增加占用率的可能性,即使这可能导致一些寄存器溢出。实际占用率远低于理论占用率,请检查指令统计实验,看是否存在高度不平衡的工作负载或尾部效应。潜在的策略可能包括以更精细的方式拆分内核网格,以更平衡的方式在块之间分配工作,避免将最终结果聚集在单个块、warp或线程上。
Pipe Utilization实验显示特定的流水线已经完全利用,增加活动warp不太可能导致更多的可执行warp,因为所有额外的活动warp将在尝试访问过度订阅的流水线时停滞。在这种情况下,请尝试减轻对该流水线的负载,或调查目标硬件的预期峰值性能是否已经达到。
读后感??
- 某些GPU中的共享内存大小和L1缓存大小是可以配置的,这是我以前没有发现的,那么没有用到共享内存的程序岂不是可以将共享内存的大小全部给L1缓存,那么加速比岂不是原地起飞?
- 一个SM单元上可以执行多个block,这个数量跟GPU的硬件限制有关系,并且跟核函数中每个块中要使用到的资源也有关系,再每种资源的总数都不超过SM单元上的配置时,那么block就可以尽可能的多。
- SM单元上会有最大的线程束的限制,要尽量让程序满足最大的线程束,这样可以拥有最高的占用率。


文章评论